
We continue our journey in the Machine Learning world we started with previous articles. We started with a dataset related to soccer matches of the Serie A. Still, we don’t know if these data allow us to create a predictive model or not, unlike those standard ones for ML courses.
In the first article, we used the cloud portal Azure Machine Learning to explore data, trying to optimize available features, thanks to some classical techniques.
In the second article, we created a console application in Visual Studio, which generated a model based on available data, thanks to the ML.Net library. What can we expect from this model? Which would be the prediction precision that player X will play n minutes or score n goals or collect n yellow cards?
The typical mistake, made while measuring the precision of a prediction, is to use the starting dataset (we can call it training dataset). The model will be obviously accurate in predicting data used to build it, but it will have low accuracy when evaluating new data.
Model performances should be evaluated based on a sample of data not used to build it. We need to keep some data out of the training dataset and, starting from them, test their accuracy. This data subset is called validation data.

(source https://cdn-media-1.freecodecamp.org/images/augTyKVuV5uvIJKNnqUf3oR1K5n7E8DaqirO)
How can we create validation data? The answer to this simple question would need a dedicated article in which to describe all available techniques, their validity, and feasibility. The only chance we have, as absolute beginners, is relying on existing tools.
We remain in the Microsoft world (similar tools also exist for Amazon and Google clouds) with the ML.NET library, we discovered in the previous article. This time we won’t work in a console application on Visual Studio, but we install the ML.NET CLI (Command User Interface) globally. The only requisite is to install the .NET Core SDK on your machine.
dotnet tool install -g mlnet

The documentation suggests us to create a console application in an empty folder

and to launch inside it the command mlnet autotrain on our dataset (which we copied in the same folder). The complete command is:
mlnet auto-train --task regression --dataset "data.csv" --label-column-name "Minutes" --max-exploration-time 500
We must choose the parameter —task among Binary Classification, Multiclass Classification e Regression. Since we need to predict a numerical value (for example Minutes or Goals), we choose Regression;
–dataset indicates the file containing our data sample, –label-column indicates the file column we want to predict;
–max-exploration-time indicates the time (in seconds) we want to give to ML.NET to explore different models. This parameter (also said training time) must be proportionate to the dataset size.
During this time interval, the CLI indicates how much time lacks, the precision of the best model (Best Accuracy), the algorithm used to reach it (Best Algorithm), and the last analyzed algorithm (Last Algorithm);

As we explored 106 models, the final result is:

A 45% Best quality is not an extraordinary result, but not even bad if we consider we started from ground zero.
We note that the CLI has also created a C# code template, that uses the generated model (MLModel.zip).

The code of the console application (SampleRegression.ConsoleApp) is very simple: as we upload the model, a prediction engine is generated starting from it.
MLContext mlContext = new MLContext();
var mlModel = mlContext.Model.Load(GetAbsolutePath(MODEL_FILEPATH), out DataViewSchema inputSchema);
var predEngine = mlContext.Model.CreatePredictionEngine<ModelInput, ModelOutput>(mlModel);
The prediction engine offers a method called Predict, which takes in input a line of new features. The model returns the prediction on the label searched by the model (Minutes in our case)
ModelOutput predictionResult = predEngine.Predict(newData);
For demonstration purposes, the generated template takes as input a line from the starting file (data.csv), showing the generated output and comparing it with the real value.

The ML-NET CLI is then a tool simple but powerful while automates a series of recurring and complex operations. Its employment allows us to move the attention to the real problem: the validity of our dataset and its prediction capability. For example, we can quickly test what happens if we change the Label (Goals instead of Minutes). The best quality decreases to 31%. Another test is to reduce the number of features in the dataset (if you remove, for example, names of teams involved and the identity of the player).

The best quality on prediction of Minutes decreases even more: from 45% to 27%.
The brute-force approach that is blindly relying on a software seems cannot bring us to a satisfactory result. Why? The answer is again in the construction and selection of features.
We start from a consideration apparently independent from the machine learning context: we are so good in solving linear problems.

(source: https://developers.google.com/machine-learning/crash-course/feature-crosses/encoding-nonlinearity)
For example: are we able to find a line that separates blue dots from orange ones? Well, sure we are! We can’t have a perfect separation, but most of the blue dots will surely be on the right side of the separation line.
What can we say about the following image instead?

(source: https://developers.google.com/machine-learning/crash-course/feature-crosses/encoding-nonlinearity )
This time we can’t find a unique separation line:

(source: https://developers.google.com/machine-learning/crash-course/feature-crosses/encoding-nonlinearity )
This is a nonlinear problem that can be solved by introducing what is called feature cross, which is a new artificial feature created from those already existing. Let’s come back to the last image and suppose we want to move the reference system as follows:

(source: https://developers.google.com/machine-learning/crash-course/feature-crosses/encoding-nonlinearity )
If x1 and x2 are both positive or both negative in relation to this new reference system, we have a blue dot. On the contrary, we have an orange dot.
We can introduce then a feature cross, x3, obtained multiplying x1 and x2.
x3 = x1 * x2
x3 can linearize our problem because its sign is able to separate blue from orange dots!
If I write the most general linear relation in terms of x1, x2, x3:
y = w1 * x1 + w2 * x2 + w3 * x3 + b
Supposing w1 and w2 are identical to 0 and w3=1, I find a separation line, even if the problem is not linear.
We can create a feature cross in many ways: multiplying five features or a feature for itself.
The introduction of a new reference system has been decisive in our example. It has been a trick, or it has a more hidden meaning? What we have done is to discretize the space of our dots and divide them into quarters, any of which has one-color inhabitants.
Incidentally, the number of inhabitants in each sector was very high. For each quadrant, we have a very high probability that a point is one of two colors.
So, if I have a new dot and I find that it is in the first quadrant (x1 and x2 > 0), I have a very high probability that the dot is blue.
Let’s take a more complex example:

(source: https://developers.google.com/machine-learning/crash-course/feature-crosses/encoding-nonlinearity)
This time four sectors are not enough to discretize our space. But we can imagine a grid of this type:

(source: https://developers.google.com/machine-learning/crash-course/feature-crosses/encoding-nonlinearity )
and for each square I will have a high percentage of dots belonging to a single category.
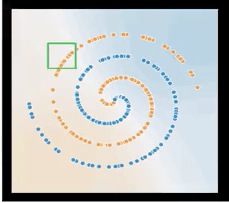
(source: https://developers.google.com/machine-learning/crash-course/feature-crosses/encoding-nonlinearity)
The technique of feature crossing requires the memorization of how we discretize our space of dots. Besides, for each cell, we must have a enough dots to make its percentage of the population statistically significant. For this reason, it is a technique that only in the last years of the ML’s life has taken hold: we need so much data to make it effective.
Are you confused? Here’s one last example that I hope will clarify your ideas.
Suppose you have a picture of a car taken in a city. From the picture, you can only see the detail of the car’s color. We wonder if it is a taxi or not. The dataset that we will use to build a predictive model will be
Color: Red, City: Napoli. Taxi? No
Color: White, City: Napoli. Taxi? Yes
…………….
Color: Yellow, City: New York. Taxi? Yes
Color: White, City: New York. Taxi? No
The linear model that uses color and city and calculates its weights has a problem.
Suppose we have a new photo in which we see a yellow car.
In most cities of the world, the color of taxis is yellow: so, we will have a very high weight for this color, and we will assign the label as Taxi even if the photo was taken in Naples.
The feature cross created by the Color and City combination, instead, linearizes the problem.
x3 = (Red and Napoli) Taxi? No
x3 = (White and Napoli) Taxi? Yes
…………….
x3 = (Yellow and New York) Taxi? Yes
x3 = (White and New York) Taxi? No
We discretized our space, and every single combination of color and city (what we called square before) has a very high (or very low) probability of the Taxi label. The new picture showing a white car in New York will have a high percentage that it is a taxi. Because in our starting dataset, we had, for example, 1000 photos of white cars taken in New York, and 80% of them were a taxi.
Our football dataset is reasonably large to be able to apply the feature crossing technique in such a way as to linearize our space and make more efficient the model generated by ML.NET. In the next article, we’ll see how.
See you soon!